Motubrain World Action Models for Robotics
Explore CapabilitiesAbout the World Action Model Motubrain

News

ShengShu Technology and Lightwheel Intelligence Establish a Strategic Partnership
Exploring practical applications of world models across real-world environments.

General World Models: Bridging Digital Intelligence and Physical Action
Connecting digital intelligence with real-world decision-making and action.

Motus: An Open-Source Unified General World Model that Outperforms Pi0.5 by 40%
Motus is now available as an open-source unified world model for embodied intelligence research.

ShengShu Technology and SimpleAI Establish a Strategic Partnership
Advancing general intelligence technologies for real-world applications.

ShengShu Technology and Anyverse Dynamics Establish a Strategic Partnership
Working together to advance the next generation of Physical AI systems.

ShengShu Technology and Astribot Establish a Strategic Partnership
Accelerating the deployment of embodied AI technologies in real-world applications.
Strategic Partners
ShengShu Technology collaborates with leading innovators in embodied intelligence to advance the General World Model ecosystem. Through strategic partnerships, we are enabling the seamless integration of General World Models and embodied intelligence, laying the foundation for the next generation of intelligent systems in the physical world.





What is Motubrain?
Motubrain is ShengShu Technology’s World Action Model for the physical world, designed as a general-purpose brain for embodied robots.
It unifies environmental perception, world modeling, and action generation within a single foundation model, enabling robots to make continuous decisions based on an understanding of the physical world, rather than relying on separate systems for perception, planning, and control. Powered by this unified architecture, Motubrain supports cross-embodiment adaptation, multi-task generalization, and long-horizon task execution, allowing robots to perform complex tasks across real-world scenarios including homes, industrial environments, and commercial settings.
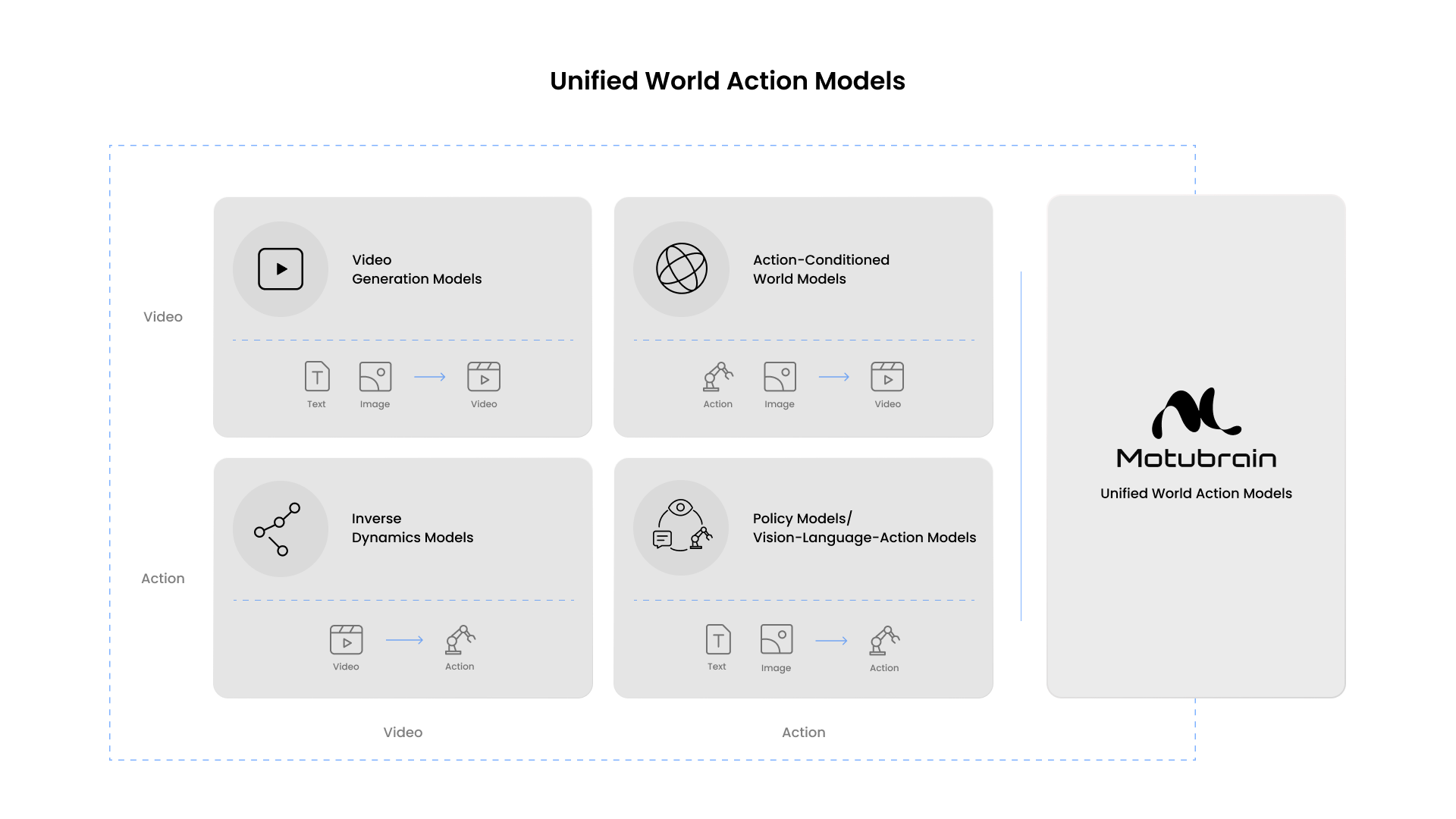
What are World Action Models?
World Action Models are the core technology behind ShengShu Technology’s Foundation World Model strategy for the physical world, serving as the bridge between the digital and physical worlds.
ShengShu Technology believes that general intelligence requires two complementary capabilities: the ability to generate the world and the ability to act within it. In the digital domain, World Generation Models learn and generate the world. In the physical domain, World Action Models understand the underlying dynamics of the physical world and enable robots to interact with and accomplish real-world tasks. Together, they form a unified Foundation World Model framework that extends AI from digital content generation to intelligent interaction with the physical world.
Unlike conventional robotic models that primarily learn action mappings, World Action Models jointly model video, action, and language to capture the shared principles governing environmental dynamics, task objectives, and robot behavior. This unified approach enables stronger generalization across tasks, embodiments, and real-world environments.
How is Motubrain related to Motus?
Motus established the technical paradigm of World Action Models, while Motubrain advances that paradigm into a general-purpose embodied AI for real-world robotic deployment.
In December 2025, ShengShu Technology released and open-sourced Motus, taking the lead in proposing and validating the core ideas behind World Action Models. Building on this foundation, Motubrain further scales up the model and introduces systematic algorithmic and engineering upgrades for real-world robot deployment, including unified multi-view modeling, unified action representation, cross-embodiment adaptation, efficient real-time closed-loop control, and inference acceleration. These advances enable large-scale embodied foundation models to operate efficiently and reliably on physical robots.
What is the difference between World Action Models (WAMs) and traditional Vision-Language-Action (VLA) models?
Traditional Vision-Language-Action (VLA) models primarily learn mappings from observations to actions, whereas World Action Models adopt a unified modeling approach that jointly learns from video, action, and language.
Rather than simply learning how robots should act, this unified framework captures the shared principles underlying environmental dynamics, task objectives, and action outcomes, enabling the acquisition of transferable world knowledge. Compared with conventional VLA models, which rely primarily on robot trajectory data, World Action Models can leverage a much broader range of heterogeneous multimodal data. This enables stronger generalization across tasks, robot embodiments, and real-world environments, while supporting better scalability and long-horizon task execution, providing a new path toward general embodied intelligence.